


Automated: how algorithms shape a day in the life and our future
Automated: how algorithms shape a day in the life and our future
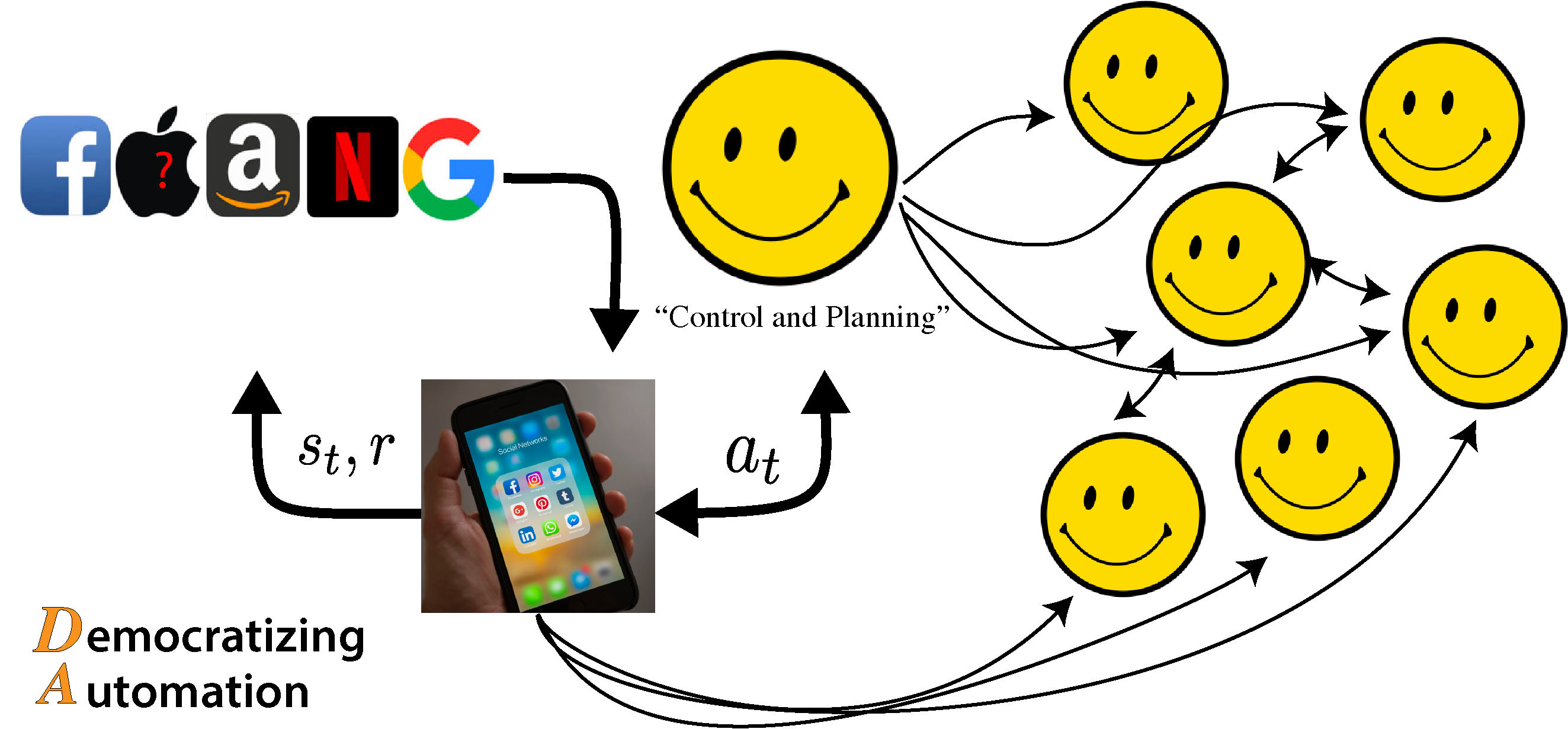
The goal of the algorithm is not to give users content they like, but to make the users more predictable. Brief added comment on online courses.

I figured the logical followup on my analysis of recommender systems from last week (it’s worth a read) would be a walkthrough of what I can learn about the algorithms that affect you and me, at a low level. This is a survey with some specific metrics companies use and a high-level analysis of themes I found. Mostly, else it turn into a full length research paper, this article is a distillation of articles I found into digestible bites, with the links to read more if you’re interested in a particular player.
Upon doing this research, there are way more points of algorithmic interaction then I expected — I mean that algorithms can touch us and interact in more ways than we expect. Someone should study the game-theory of algorithmic competition within human brains. How does TikTok’s algorithm help it hold onto users that Youtube may pull? Hopefully this is a starting point if people want to figure out how an app works.
If you want to get the most value out of this post, click a couple links.

A general theme of recommender systems and these platforms is: if we can predict what the user wants to do, then we can make that feature into our system.
The general problem formulation is: how compounding interactions change how we act and can harm our well-being.
The core players
Facebook, Apple, Amazon, Netflix, and Google (FAANG) are often the most coveted companies to work for, and they have an outsized effect on the population of the world. This article does not go into all the geopolitical and ethical issues of the companies, it just tries to show how they work, a bit.
The algorithm is designed to show individuals things in their circles, and get them to engage with it. This considers the contents’ sources, the geographic location of the user, the social position of the user, the history of user engagements, paid advertisements, and more. The algorithm has been studied well enough to realize it has a dramatic effect, but conditioning on any one input is impossible, hence common references as a dangerous black box. A second-order effect of this is that the algorithms end up predicting which circle you are in, and guiding you to the middle of it (sometimes called polarization if your circle was a moderate, to begin with).
I use Instagram off and on, and the biggest effect is likely to drive me to try and glamorize my life, but thankfully I consider the effects minor.
[Sources: WSJ, WSJ2, Verge, Facebook AI]
The algorithm is like Facebook’s, but more prone to vitality — especially for users that start with a large audience. From Twitter itself, it considers the following features:
The Tweet itself: its recency, presence of media cards (image or video), total interactions (e.g. number of Retweets or likes)
The Tweet’s author: your past interactions with this author, the strength of your connection to them, the origin of your relationship
You: Tweets you found engaging in the past, how often and how heavily you use Twitter
Honestly, this doesn’t say much. Given Twitter’s quirks, I could see them having an obscure end-to-end optimizer and not many controls.
I am definitely addicted to the knowledge vitality and access to other intellectuals on Twitter. These blue notification bubbles get me.
[Sources: Sprout Social, Twitter Blog, Hootsuite - a social media marketing company]
YouTube
A mysterious entertainment platform upon closer inspection. While governed by a public American company, there have been multiple studies showing recommendations tracking pathways to radicalization (See NYT below) and even showing children troubling material (NYT2). The wealth of content available makes series’ of recommendations incredibly depth and impactful. I would like to see more public insight, now that the company is competing with TikTok.
I consume a lot of my casual content on Youtube. I think that watching Joe Rogan clips has gotten me some Trump ads (Yes dramatically more for Biden), but it makes me think about how the videos I am watching can drift.
[Source: NYT, NYT2, Shopify - yes they analyze the Youtube algorithm?]
As the first widely useful search engine, everyone uses Google. Google uses a variety of tools to index webpages (see PageRank as the origin) including text, links to other pages, history of readers on the site, and more. Its hand in the dissemination of information is crucial, and I worry that it has biases that are impossible to track.
Their position is now more precarious in the context of anti-trust hearings and competitors. In recent years, Google shifted its results to include many more ads and self-referencing results (especially in profitable searches like travel and shopping). This self-referencing is what I see as a competitive angle against Google.
Google controls how I find other academic papers, blogs, news, and more. I don’t know how to measure the effects beyond big.
[Source: WSJ, The Mark Up, Search Engine Journal]
The coming players
These are areas where I see algorithms coming into play in new ways, and particularly in ways that may disadvantage some and or have deleterious effects.
News
Classical media shifting online (New York Times, Wall Street Journal, etc.) and new online-only publications (Medium, etc.) will corral our political and global world views. Clickbait has shifted into reading time, but that changes from a clickbait title to a clickbait title + a readbait introductory paragraph. I saw the effects of this in my own Medium articles - my writing was being tuned to the algorithm (and it worked - tutorials, code examples, and lists get more views than in-depth analysis). The reading population of the world is re-emerging on Substack (and other platforms - such as context is recent events).
Beyond clickbait, the New York times is beginning to use research engagement algorithms on the news platform(specifically, something called contextual bandits - context in research). To be blunt, when I read the news I want to read the events with minor added opinions. I do not want control over how I receive national and global news, but it is an expected development.
Medium drove me away from clickbait to Substack (here). I am subscribing to more newsletters and could see myself unsubscribing from NYT and WSJ if trends continue too far. The picture of America being ruined solely by Trump is too narrow-minded from me and not giving me a broad enough education.
[Sources: NYT]
Shopping
Amazon wants to be the go-to search engine for shopping. They are expanding into many different areas of shopping (e.g. groceries, retail, and more soon) to get a bigger picture of individuals needs. When you ask Alexa to remind you of something, that could be recorded too. These form a multi-modal recommender system for ads and sales.
Facebook created a new marketplace to try and fight Amazon’s rule. Facebook wants to be a middle man with Shopify (Shopify isn’t an Amazon competitor without other companies) and vendors to create a platform where people can buy anything. With differing incentives (financials), it will be interesting to see how this plays out.
I have taken steps to use Amazon much less. Its recommendations are weird, is filled with duplicate content, but is still incredibly convenient. The prospect of the Facebook marketplace makes me think of a more automated customer-vendor connection.
[Sources: Recipe Express, Axios, Sellics]
Services
New applications are coming to offer value across many areas: including financial market access, customer analysis, ride-sharing, and more. These services will have less public oversight, to begin with, but time will show that multiple of them will have extremely harmful algorithmic effects. I include services in the coming players because the timescale from adoption to problem will be very short (apps can explode in usership, see the example of Zoom). The negative metrics usually lag behind adoption, except in the example of the least thought through service maybe ever.
[Sources: UC Berkeley on Fintech, Genderfying AI Fail, GIG Economies]
Second order effects
These are current applications that are undiscussed and deserve to be questioned on possible side effects (of initially positive applications).
Consumer devices
Apple watches attempting to detect atrial fibrillation for their users opens a huge problem of false-positives (see StatNews below). Technology companies will without a doubt attempt to add more features to their devices, and with a market penetration of millions of users, the inevitable false positive rate will have potential medical and financial implications. The compounding effect of these devices and misleading datapoints is left to be observed in the 2020s - with the uninformed most at risk.
[Sources: Apple, StatNews, Oura]
Public medical / health tools
There are many new companies in the health space, such as Strive.ai that’ll analyze workouts and Bloodsmart.ai that’ll analyze blood tests to give you a health score (based on normalized, age-adjusted risk of death). This is preliminary, but gamifying one’s health is coming. Only a few steps after Apple’s “fill the rings” watch campaign is health-dashboards telling users how their habits may be numerically shortening their life.
I don’t use that many trackers now, but simply having a readout of estimated calories on my watch caused me to be self-conscious of eating too much when not working out in a day. This problem would be compounded with noisy readings on blood-markers or emotional well-being.
[Sources: Strive, Bloodsmart]
Isn’t this a robotics blog?
Everything we have said in the last two iterations of Democratizing Automation regarding recommenders and algorithms will apply to robotic systems in the next decade. I forecast a dramatic increase in the penetration of robotic-human interaction with the incentives of the robots governed (for the most part) by big technology companies (informed by some research).
The few smaller companies making personal robots may seem more exciting (e.g. Hello Robotics), but that market share will be relatively small to start with (high-cost) while many companies can afford to replace the human cashier and salesperson with an embodied autonomous agent.
I made a resource tracking when these algorithms go wrong and some philosophical background.
Hop on or Fizzle out (in education)
Universities are going to quickly fall behind with online courses if they don’t innovate. Translating university courses in their current form online will not be sustainable. After teaching a section the other day with 13 participants that took 15minutes to speak up in a form other than the Zoom chat box, I realized things have to change. For reference, I say 1.5 students were conversing with me for the rest of the section. It was pretty much an open room tutoring session that was recorded for people to watch later. Bizarre. This extends to lecture, but becomes an even more challenging question: Should lectures have variable lengths based on content? Some long form and some short form? Please chime in if you have ideas.
Engagement with no socialization will be the death of how colleges used to operate. I have some more solutions to offer:
Compulsive attendance-based grading metrics. In my piece online courses, automating education, and digitalizing degrees, I talked about the synchronicity vs coverage problem and how universities will try to accomodate global students — this won’t work without an outlay of resources. Students need to be given set times where they can engage in small groups.
Less time teaching, more time making. In a traditional class, there are 3-9 staff members that teach roughly the same material every week. In an online only course, this number should reduce to 1-2 teaching staff and the rest creating engaging content. I propose having people spend 2-3 weeks creating an instructive lab material (Jupyter notebook or something similar) and having most students continue to watch the recordings.

The tangentially related
I am reading (newsletters/blogs):
A brief history of deep learning’s rocket trajectory into commonplace.
How neural networks can cheat if you give them shortcuts in the data.
Random Americans getting unmarked seeds from China. Uhm, please don’t plant these. Crazy to follow, though.
Books:
White Fragility - Robin DiAngelo. It’s not about you feeling bad for saying something they interpreted as racist, it’s about you changing and understanding you are part of the system. Try to be better every day.
I am listening to / watching:
The Drive - Peter Attia with Azra Raza, “Why we’re losing the war on cancer.” Treatments for metastatic cancer have not improved life expectancy since the 1930s. We have improved early detection and prevention, but once people have serious cancer, research has not solved that (even with over $250Billion spent on research). We need to rethink how cancer research is done.
Hopefully you find some of this interesting and fun. You can find more about the author here. Tweet at me @natolambert, email democraticrobots@gmail.com. I write to learn and converse. Forwarded this? Subscribe here.